Chameleon
Style-Content Disentangled Framework for Cross-Domain Object Compositing
arXiv 2026
The first large-scale dataset, benchmark, and two-stage framework for cross-domain compositing, preserving foreground identity while enabling realistic stylization through style–content disentanglement and adaptive style injection.
† Co-corresponding authors


The problem
Why is cross-domain compositing hard?
Cross-domain compositing is a challenging task that requires placing a foreground object onto a background across heterogeneous domains, preserving the identity of the foreground while transferring the style of the background for seamless integration.
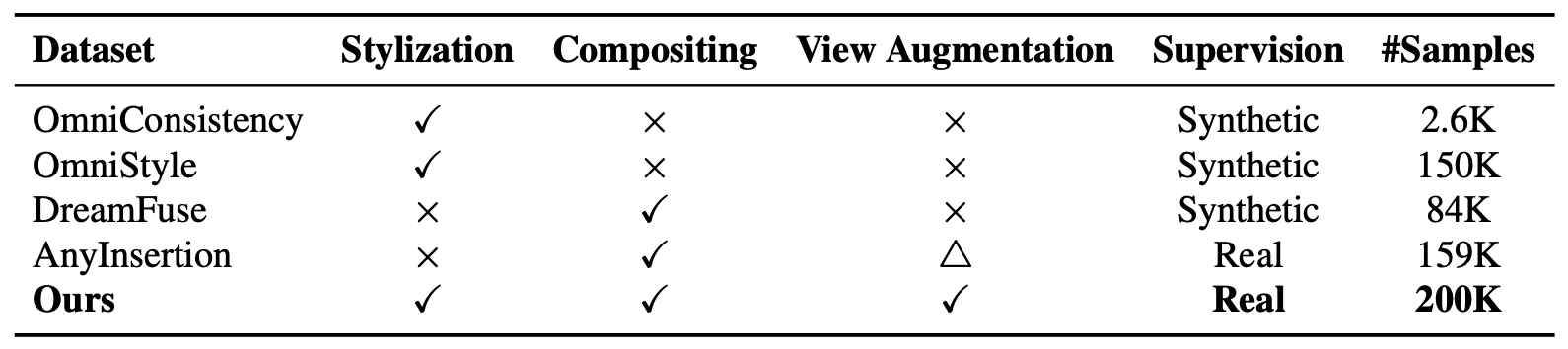
Lack of large-scale paired data
Existing cross-domain compositing approaches largely rely on training-free blending and refinement strategies, partly due to the lack of large-scale paired datasets, limiting the development of training-based solutions.
Recent strong semantic encoders such as DINOv3, largely underexplored for stylization
Recent self-supervised encoders such as DINOv3 have demonstrated transferability across classification and segmentation. Yet their capacity as a style encoder remains largely underexplored. Naive use of DINO leads to content leakage (Figure 1).

(c) Our ChameleonEncoder (style head) globally distributes attention, capturing background style rather than content, for faithful compositing.
Naive style injection across all tokens is suboptimal
The background already preserves its own appearance statistics in the VAE latent, so naively allowing the style token to attend to all latent tokens (including those of the background) is suboptimal.
Method
Reverse Dataset Construction Pipeline
Prior approaches adopt a forward data generation pipeline that constructs the supervision target from synthetic generations, yielding an inherently suboptimal mapping regardless of model capacity. Our reverse pipeline inverts this construction process, starting from curated real stylized composite images Ic as ground-truth to ensure faithful, artifact-free supervision.
Figure 3. Five-stage reverse construction pipeline starting from real stylized composites Ic.
ChameleonEncoder
Two heads (style and content) on a shared DINOv3 backbone are trained with the Joint Hard Contrastive Learning (JHCL) loss to disentangle style and content embeddings.
Figure 4. ChameleonEncoder training via Joint Hard Contrastive Learning (JHCL).
Figure 5. Encoder embeddings visualization (t-SNE, 8 styles). Naive DINO and HCL yield entangled representations, while JHCL produces disentangled style clusters.
Cross-Domain Compositing Model
Our framework injects disentangled content and style tokens from ChameleonEncoder (Stage 1) into a DiT backbone. Our key contribution is Spatio-Temporal Attention Gating (STAG), which adaptively regulates style injection across both spatial and temporal (diffusion timestep) axes for effective cross-domain compositing.
Figure 6. Stage 2 cross-domain compositing model. Content and style tokens from ChameleonEncoder are injected into a DiT, with style tokens regulated by STAG.
Experiments
Click each question to expand the evidence.
Part I
Main Results & Design Choices
Yes. Chameleon consistently outperforms two-stage and commercial baselines across qualitative results (Figure 7) and identity (CLIP-I), stylization (CSD), and compositional VLM metrics (Table 2).
Figure 7. Cross-domain compositing results by our Chameleon. (a) preserves foreground identity, (b) maintains consistent style, and (c) aligned geometry and (d) grounded shadows demonstrate compositional plausibility. (e) Chameleon outperforms two-stage cascaded pipelines that combine style transfer and object insertion (over-stylizing the foreground), as well as commercial models (GPT-Image 2, Nano-Banana 2) that shift background tone or ignore the input mask.
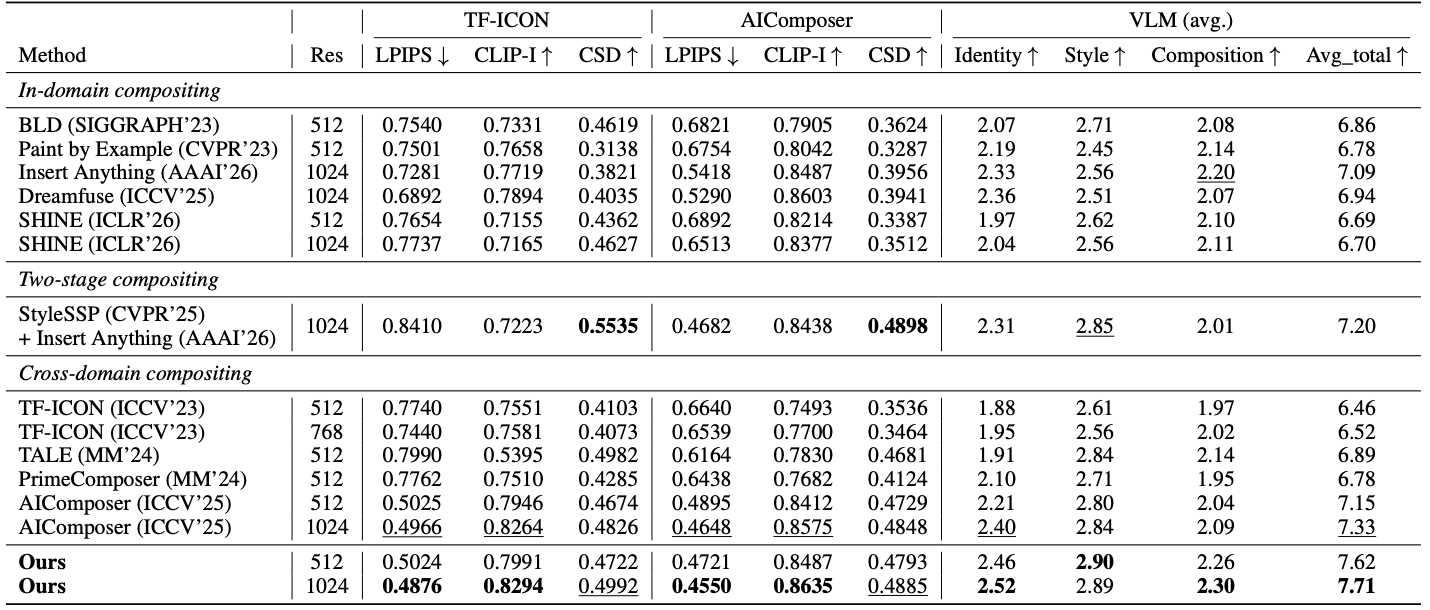
Table 2. Quantitative comparison on TF-ICON and AIComposer benchmarks. Our Chameleon achieves best results across metrics measuring identity, stylization, and compositionality. CSD is the only second-best result, since high CSD on the 2-stage cascaded pipeline reflects over-stylization (Figure 7(e)).
DINOv3 achieves the strongest overall disentanglement margin Δ among frozen off-the-shelf encoders (Table 3), making it the most suitable foundation for training built upon our proposed JHCL loss. Within DINOv3, mid layers (12-14) yield the smallest negative margin on the style-paired split while late layers (18-20) provide substantially stronger content separation (Table 4), motivating why DINOv3 and these layers (12-14 for the style head, 18-20 for the content head) are selected.
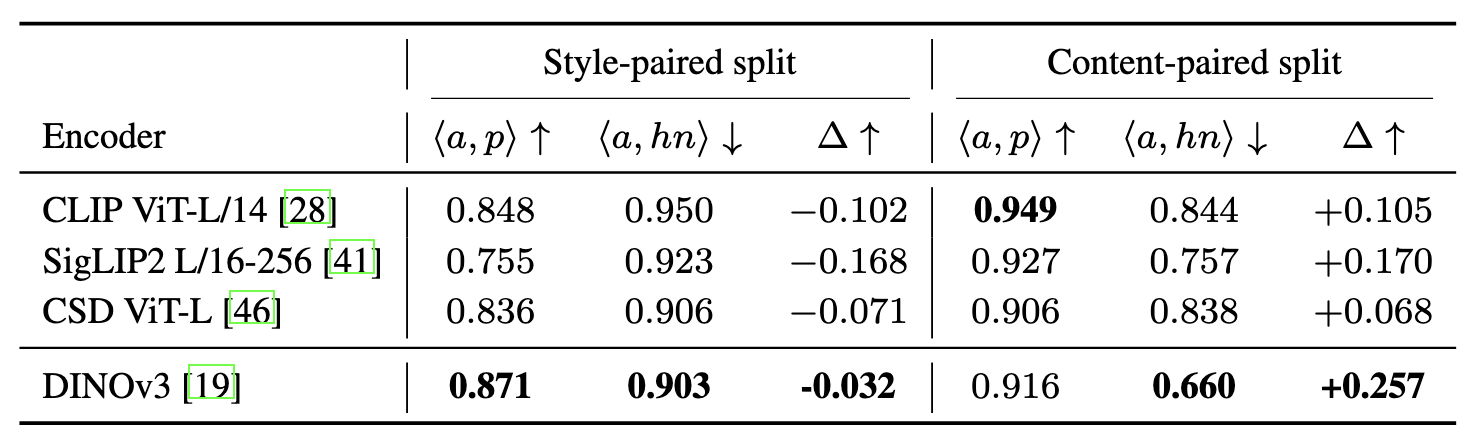
Table 3. Why DINOv3? Disentanglement margin Δ on the dual-anchor test across frozen off-the-shelf encoders (without any projection head). DINOv3 achieves the strongest overall margin, especially on the content-paired split.
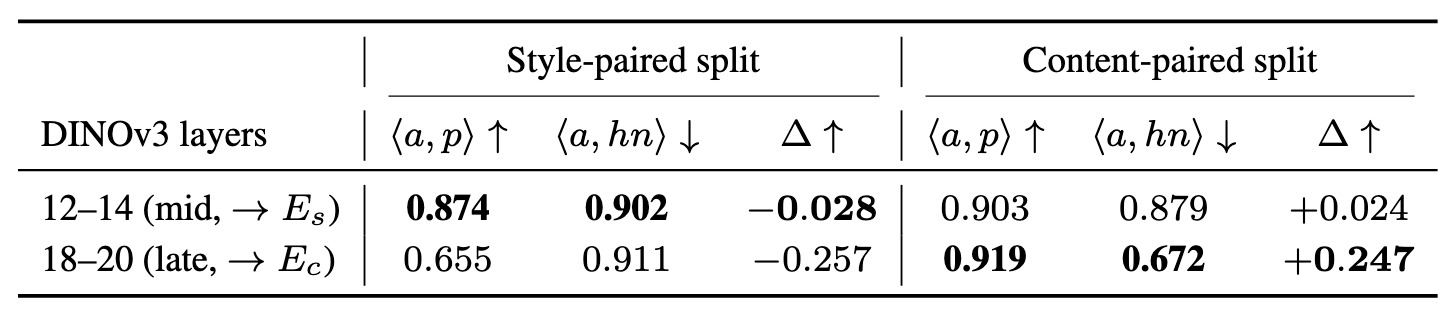
Table 4. Layer selection for the style and content heads. Within DINOv3, mid layers (12-14) yield the smallest negative margin on the style-paired split, while late layers (18-20) provide substantially stronger content separation.
Part II
Analysis
Yes. STAG adaptively gates style injection across both spatial and temporal axes. (a) Spatially, attention concentrates on the foreground region. (c) Temporally, stronger stylization emerges at later denoising steps, aligning with prior research, but unlike prior fixed schedules, we condition adaptively on the denoising stage via learnable gating. (d) Per-block gating dynamically activates and suppresses style injection without collapsing.
Figure 8. Effect of Spatio-Temporal Attention Gating (STAG). Attention from the foreground query (white box) to ST(Ibg). (a, b) STAG-on / STAG-off attention maps. (c) Per-step attention to ST(Ibg) across denoising steps. (d) Per-block amplification ratio (STAG-on / STAG-off).
Yes. Prior benchmarks such as TF-ICON inflate sample count via foreground × background combinations (10 × 10 = 100 redundant pairs) and remain limited to simple compositional scenarios. In contrast, ChameleonDatasetev evaluates challenging cross-domain cases, including (a) foreground-background interaction, (b) lighting-grounded shadows, (c) reflective surfaces, and (d-g) diverse unique background styles.

Figure 9. Representative cases in ChameleonDatasetev. (a) Natural foreground interaction (climbing stairs). (b) Lighting-consistent shadow grounding. (c) Reflection on reflective surfaces. (d-g) Diverse background styles (motion blur, mosaic, pixel-art, grayscale).
Yes. Only +0.21% trainable parameters relative to the frozen DiT backbone (Table 5), and adding 392 DINO tokens (196 style + 196 content) incurs < 1s latency overhead (+0.22s on res 512, +0.55s on res 1024, 28-step) (Table 6), while heads trained from the JHCL loss output tokens that improve both identity (CLIP-I) and stylization (CSD), and STAG further boosts stylization metrics (CSD, AES) (Table 7).
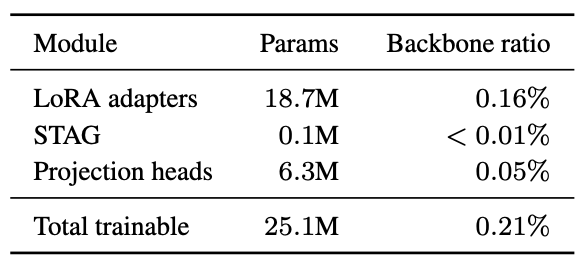
Table 5. Trainable parameter budget. STAG adds only 0.1M params (<0.01% of the backbone).
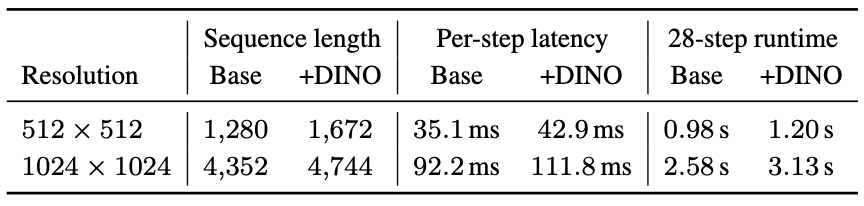
Table 6. Inference overhead from +392 DINO tokens (196 style + 196 content). Adds +0.22s on res 512 (0.98s → 1.20s) and +0.55s on res 1024 (2.58s → 3.13s) for 28-step inference.
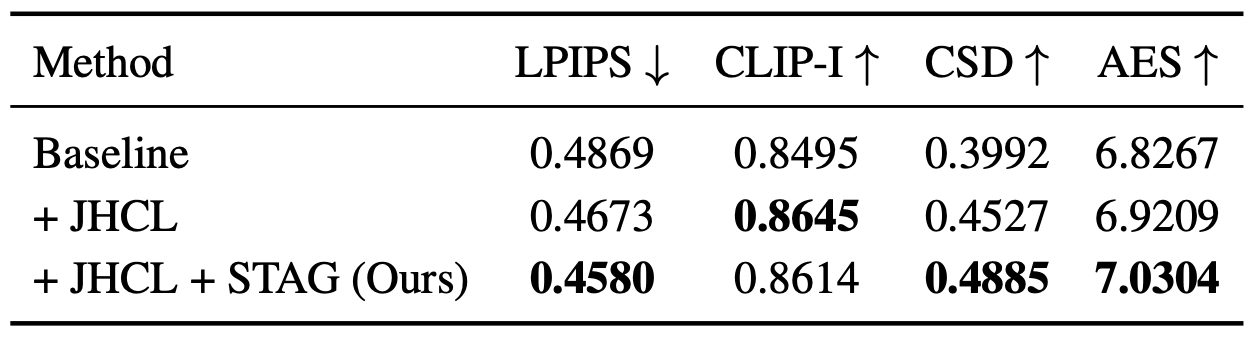
Table 7. Component ablation. JHCL improves both identity (CLIP-I) and stylization (CSD); STAG further improves stylization metrics (CSD, AES).
Citation
BibTeX will be available upon arXiv release.