TL;DR We present MoCHA-former, a video demoiréing transformer that decouples moiré from content and enforces spatio-temporal consistency, achieving state-of-the-art results on RAW and sRGB datasets.
Demo
Moiréd Input Video
Result of MoCHA-former
Comparison between the moiréd input video and the result of MoCHA-former.
Abstract
Recent advances in portable imaging have made camera-based screen capture ubiquitous. Unfortunately, frequency aliasing between the camera’s color filter array (CFA) and the display’s sub-pixels induces moiré patterns that severely degrade captured photos and videos. Although various demoiréing models have been proposed to remove such moiré patterns, these approaches still suffer from several limitations: (i) spatially varying artifact strength within a frame, (ii) large-scale and globally spreading structures, (iii) channel-dependent statistics and (iv) rapid temporal fluctuations across frames.
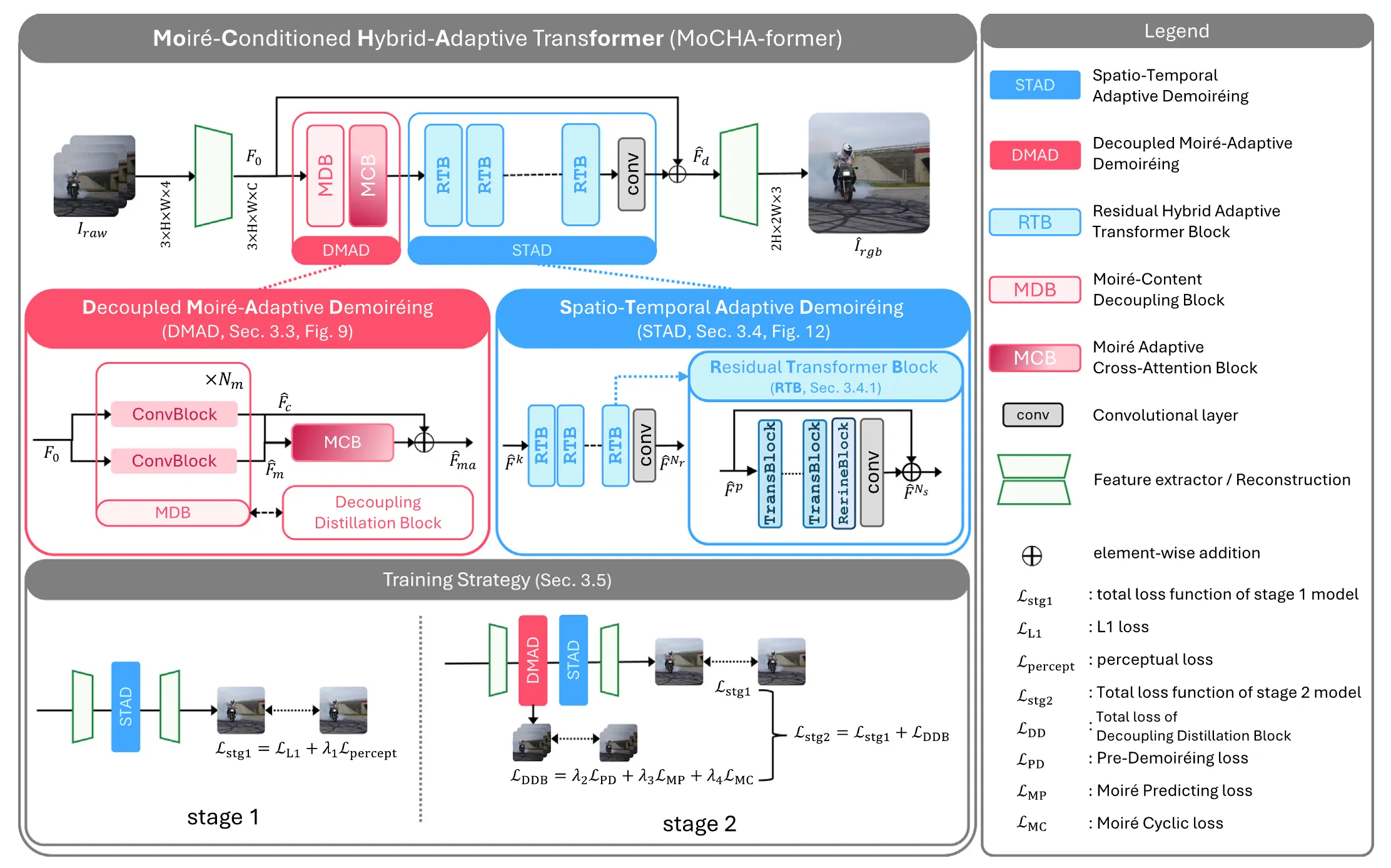
We address these issues with the Moiré Conditioned Hybrid Adaptive Transformer (MoCHA-former), which comprises two key components: Decoupled Moiré Adaptive Demoiréing (DMAD) and Spatio-Temporal Adaptive Demoiréing (STAD).
DMAD separates moiré and content via a Moiré Decoupling Block (MDB) and a Detail Decoupling Block (DDB), then produces moiré-adaptive features using a Moiré Conditioning Block (MCB) for targeted restoration. STAD introduces a Spatial Fusion Block (SFB) with window attention to capture large-scale structures, and a Feature Channel Attention (FCA) to model channel dependence in RAW frames. To ensure temporal consistency, MoCHA-former performs implicit frame alignment without any explicit alignment module. We analyze moiré characteristics through qualitative and quantitative studies, and evaluate on two video datasets covering RAW and sRGB domains. MoCHA-former consistently surpasses prior methods across PSNR, SSIM, and LPIPS.
Method
Our proposed MoCHA-former consists of two components: (i) DMAD and (ii) STAD. DMAD aims to separate moiré patterns from content and generate moiré-adaptive features. STAD takes the moiré-adaptive features as input and focuses on removing moiré patterns in a spatio-temporal manner.
Overview of our proposed video demoiréing framework, Moire-Condtioned
Hybrid-Adaptive Transformer (MoCHA-former). The overall framework consists two key
modules. (1) Decoupled Moiré-Adaptive Demoiréing module (DMAD) and (2) Spatio-
Temporal Adaptive Demoiréing module (STAD).
Quantitative Results
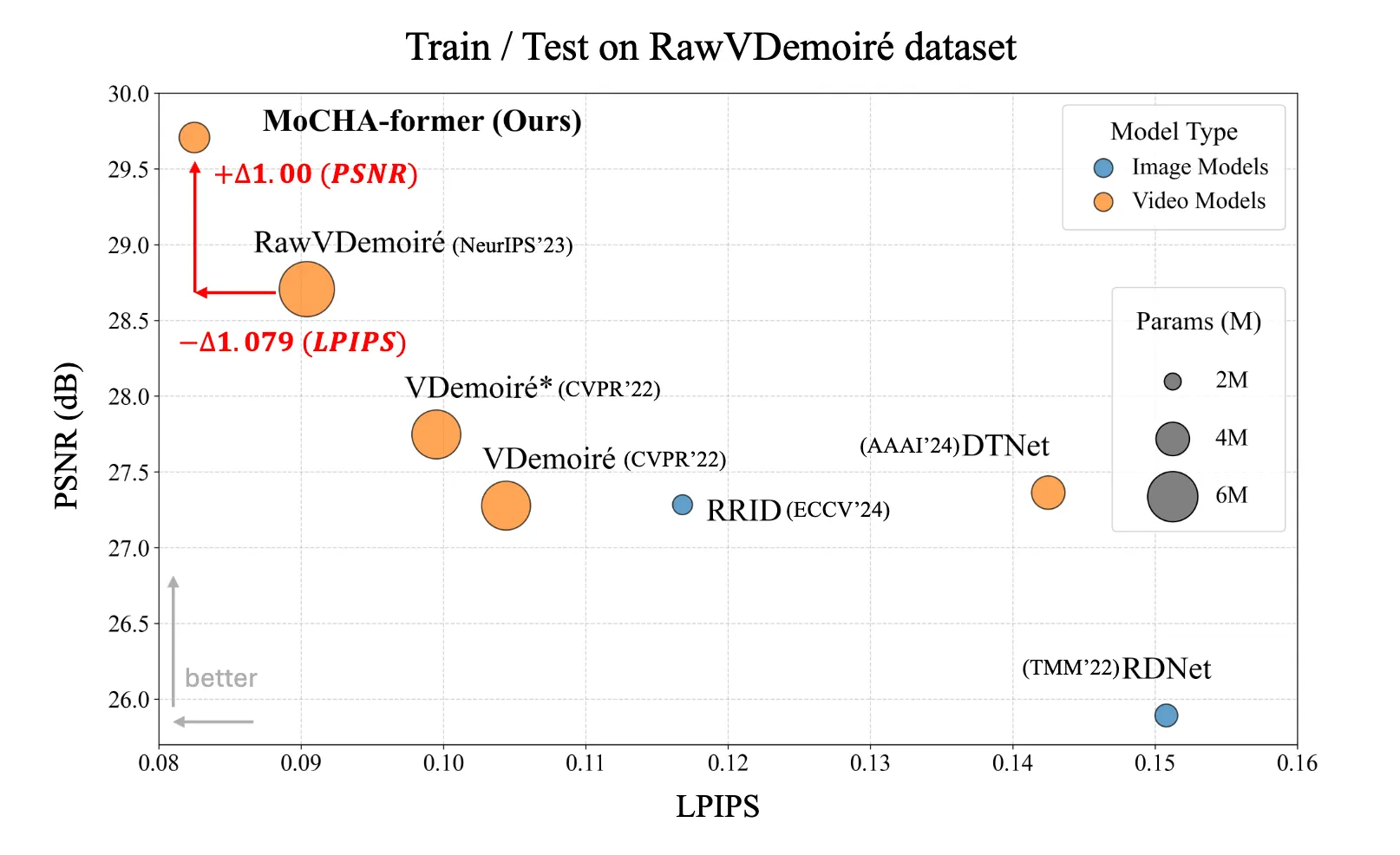
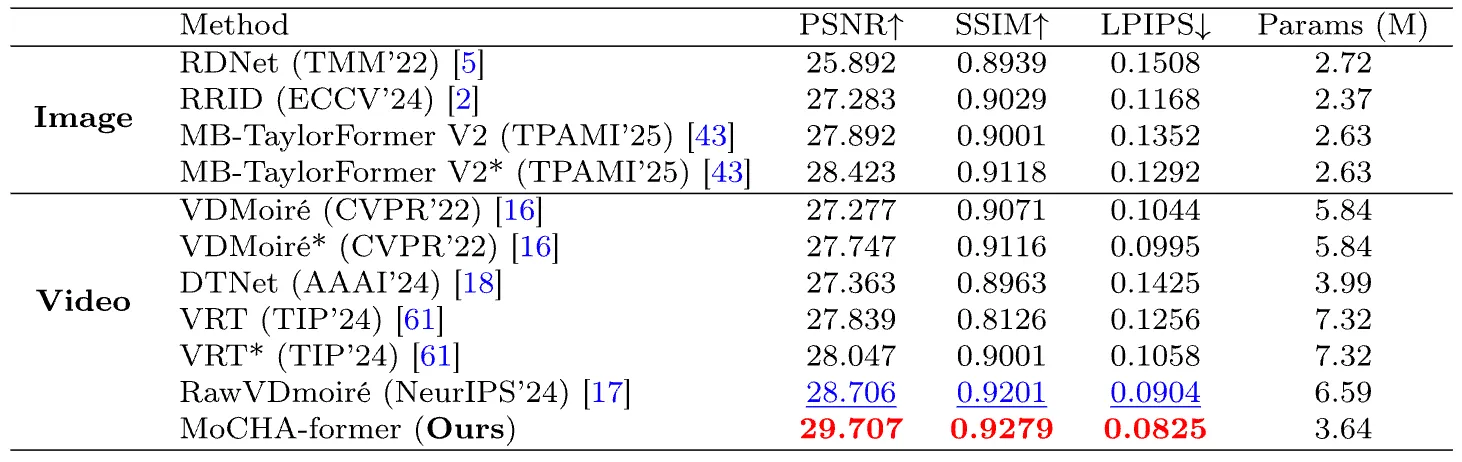
Our MoCHA-former outperforms previous methods [17, 16, 2, 18, 5] in both PSNR↑ and LPIPS↓ while using fewer parameters.
Comparison of image and video models in RAW video demoiréing dataset (RawVDemoiré dataset). The symbol “∗” denotes a model originally designed for processing sRGB images, which has been modified and retrained to handle RAW inputs.
Comparison of image and video models in sRGB video demoiréing dataset (VDemoiré dataset).
Qualitative Results
Qualitative results on the RawVDemoiré dataset. (a) shows the input
moiréd frame, (e) is the corresponding ground-truth frame, and (b)-(d) present the results
of RRID, RawVDemoiré, and MoCHA-former (Ours), respectively. As highlighted
by the red boxes and arrows in (b), RRID fails to fully resolve the color distortion compared
to Ours and retains stripe-like moiré patterns. Similarly, as indicated by the red boxes
and arrows in (c), RawVDemoiré does not completely remove grid- or stripe-like moiré
artifacts. In contrast, Ours effectively removes both grid and stripe moiré patterns while
also restoring accurate color appearance.
Qualitative results on the VDemoiré dataset. (a) shows the input moiréd
frame, (e) is the corresponding ground-truth frame, and (b)-(d) present the results of
VDemoiré, DTNet, and MoCHA-former (Ours), respectively. As observed in (b),
VDemoiré fails to resolve the color distortion across the entire frame compared to Ours.
In (c), DTNet alleviates the overall color distortion; however, as highlighted by the red
boxes and arrows, localized color artifacts from moiré patterns remain, and stripe-shaped
moiré structures are still present. In contrast, Ours removes most of the stripe-shaped
moiré patterns while simultaneously restoring the correct color appearance.
BibTeX citation
@article{sung2025mocha,
title={MoCHA-former: Moir{\'e}-conditioned hybrid adaptive transformer for video demoir{\'e}ing},
author={Sung, Jeahun and Roh, Changhyun and Eom, Chanho and Oh, Jihyong},
journal={Neurocomputing},
pages={132477},
year={2025},
publisher={Elsevier}
}